Vivek Raghavan and Pratyush Kumar didn’t build for India’s AI market. They built for the parts of it global models couldn’t reach.
Sarvam AI, an Indian AI infrastructure startup building sovereign large language models, is in advanced discussions to raise $200–250 million at a $1.5 billion valuation — signaling a structural shift in how AI systems are designed for non-English, low-latency environments.
At a surface level, the round resembles another late-cycle AI funding surge. In reality, it represents something far more important: the moment a non-consensus founder thesis transitions into market consensus.
For years, the global AI ecosystem operated on a quiet assumption — that markets like India would adapt to systems built elsewhere. Sarvam was founded on the opposite belief: that India’s linguistic, infrastructural, and economic realities required a fundamentally different architecture from the ground up.
That conviction, once considered niche, is now being repriced at unicorn scale.
The Founding Conviction the Market Missed
Raghavan and Kumar did not begin with a product roadmap. They began with a constraint.
India is not an English-first or high-bandwidth digital environment, nor is it fundamentally text-centric. Instead, it is a system defined by large-scale multilingual usage, voice-dominant interaction patterns, and significant constraints around latency, device capability, and cost.
Most global AI systems treat these characteristics as edge cases to be adapted to. Sarvam treated them as the core design principle.
The dominant approach — fine-tuning global foundation models such as GPT-4 or Gemini for Indian use — produces workable outputs, but it does not solve the underlying structural mismatch. It adapts the interface layer without rethinking the system itself.
In 2023, Raghavan and Kumar made a decision that diverged sharply from industry norms:
Build from first principles — in India, for Indian conditions, from the first token.
That decision did not just shape the product. It defined the company’s entire strategic position.
Execution: What Was Actually Built
The valuation narrative obscures the more important signal: execution discipline.
Sarvam did not remain conceptual. It shipped across multiple stages:
- an initial 3B parameter model
- a 30B model marking scale transition
- and ultimately Sarvam 105B, a frontier mixture-of-experts architecture
This system was trained on:
- more than 16 trillion tokens
- 22 Indian languages alongside English
- domestic GPU infrastructure, including Yotta clusters
The benchmarks are not symbolic. Across Indic reasoning, document processing, and multilingual workflows, Sarvam performs at parity — and in certain domains exceeds — comparable global models.
This is not a fine-tuned derivative.
It is a sovereign foundation model built natively for its environment.
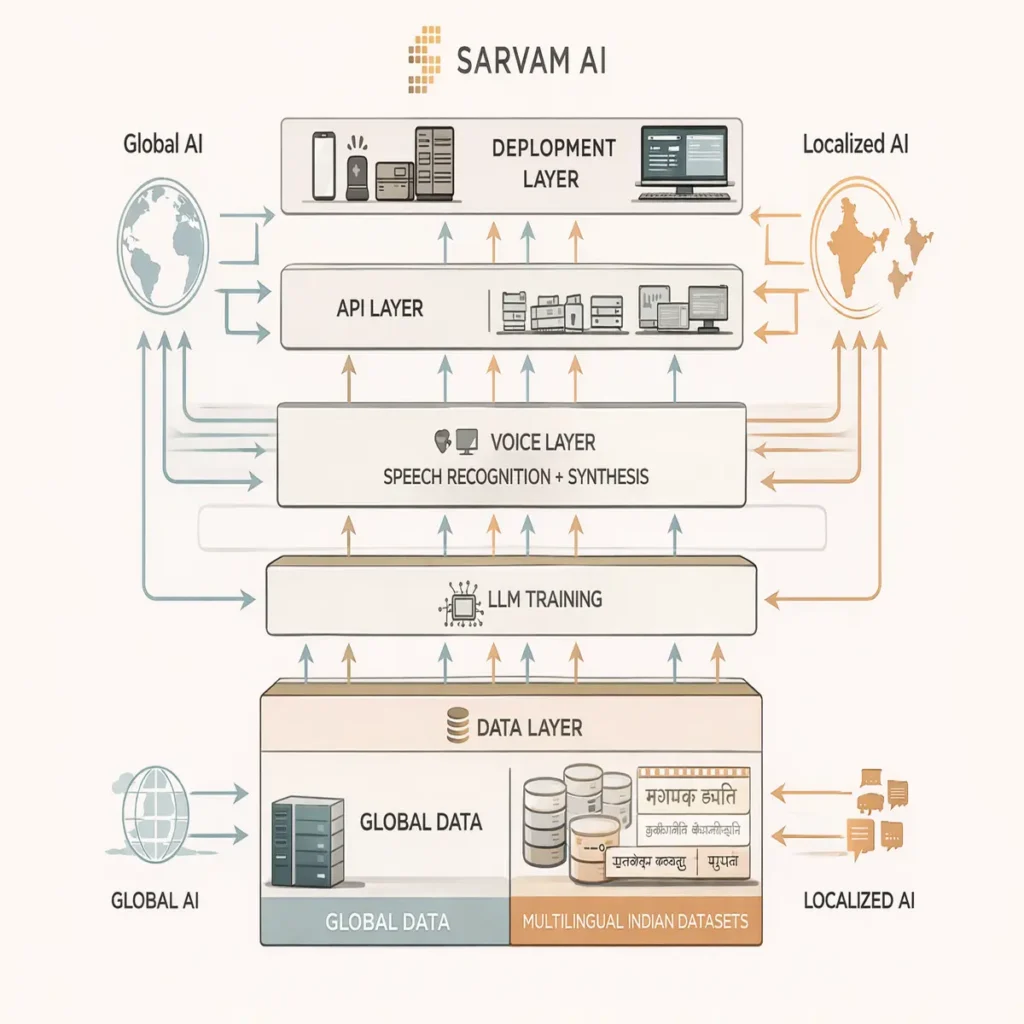
Beyond Models: Building the Stack
What distinguishes Sarvam is not just model capability, but system completeness.
The company has built multiple layers required for real-world deployment:
- voice systems (Bulbul, Saaras) optimized for Indian phonology
- a document intelligence layer capable of handling semi-structured multilingual workflows
- an API ecosystem enabling local developer adoption at scale
These are not theoretical components. They are already integrated into live systems, including UIDAI and SBI Life pilots reaching tens of millions of users.
At this stage, the classification becomes clear:
Sarvam is no longer a research organization. It is becoming infrastructure.
And infrastructure, unlike tools, compounds in value over time.
Why Nvidia Changes the Equation
Nvidia’s involvement should not be interpreted as capital participation alone. It represents strategic alignment at the most critical layer of the AI stack: compute.
Sarvam has already demonstrated:
- inference optimization on Blackwell architecture
- a reported 4× throughput improvement over H100 baselines
- allocation of 4,096 H100 GPUs through the IndiaAI Mission
An investment formalizes this relationship into privileged access.
In a market where GPU supply remains constrained, this creates structural advantage. Compute availability becomes less dependent on open-market competition, while optimization moves closer to the hardware layer itself.
In effect, Sarvam transitions from being a customer of the AI stack to becoming part of its strategic ecosystem.
That is not funding.
It is validation at the infrastructure layer.
Founder Psychology: Why This Worked
The rapid valuation expansion — from approximately $200 million to $1.5 billion — cannot be explained by market conditions alone.
It is the outcome of a series of deliberate, non-consensus founder decisions.
First, Sarvam open-sourced model weights at a time when the broader industry was moving toward closed systems. This accelerated ecosystem formation, improved benchmark visibility, and established early category ownership.
Second, the company optimized for edge deployment and low-cost inference rather than hyperscale cloud environments. While this limited short-term upside, it aligned directly with India’s real compute consumption patterns, expanding long-term market potential.
Third, Sarvam remained focused on infrastructure rather than launching consumer-facing applications. This reduced visibility in the short term but created deeper dependency across the ecosystem.
Individually, these decisions appeared conservative.
Collectively, they created structural inevitability.
Krutrim vs Sarvam: Diverging Founder Strategies
The comparison with Krutrim is best understood as a divergence in philosophy rather than competition.
Krutrim, led by Bhavish Aggarwal, represents a vertically integrated model — combining hardware, applications, and distribution within a capital-intensive framework.
Sarvam represents the opposite approach: horizontal infrastructure, focused on models, APIs, and ecosystem enablement, with a more capital-efficient structure.
One seeks to control the stack.
The other aims to power it.
In the current investment environment, infrastructure narratives are easier to underwrite, while distribution-led models face greater execution complexity. This partially explains the difference in valuation trajectories.
What the Capital Actually Unlocks
The next phase of Sarvam’s development is not centered on research breakthroughs, but on scale.
Capital will be directed toward:
- expanding private GPU infrastructure
- reducing inference costs
- converting enterprise pilots into contracted revenue
- deepening government integration
- building multimodal and agentic system layers
The potential involvement of HCLTech is particularly significant, not as a financial contributor but as a distribution channel into institutional systems.
At this stage, access matters more than invention.
The Structural Shift
Sarvam is not building “Indian AI” in a narrow sense.
It is building AI infrastructure aligned with India’s operating reality.
This distinction is critical.
The global AI stack is built on assumptions of English dominance, cloud-first deployment, and high-bandwidth availability. India diverges from all three.
This pattern is increasingly visible across AI infrastructure:
- Control layers replacing observability systems
- Execution-layer AI transforming real-world workflows
- AI-native infrastructure redefining cloud systems
Sarvam extends this shift into language itself:
👉 Language is becoming infrastructure
The Longer Arc
Raghavan previously contributed to India Stack — a foundational layer that transformed digital payments across the country.
Sarvam reflects a similar ambition applied to AI.
Not an application.
A foundational system.
The comparison remains early, but the structural pattern is consistent: identify the constraint, build the infrastructure, and enable the ecosystem.
Editorial Close
This is not a funding story.
It is a repricing event.
The market is not betting on future growth alone. It is recognizing that the system Sarvam set out to build is already taking shape.
And once infrastructure exists, everything else does not compete with it.
It builds on top of it.
Research Context
This analysis is based on publicly available information including Moneycontrol reporting (March 2026), India AI Impact Summit disclosures, Sarvam AI model releases and benchmark data, Nvidia collaboration signals, and comparative analysis of Indian AI infrastructure players such as Krutrim. Additional context is derived from broader industry trends in sovereign AI, low-resource language modeling, and infrastructure-layer capital allocation.
Editorial Note
This article reflects independent analysis of publicly available data and broader AI infrastructure trends. It is intended to provide structural insight into founder strategy, capital allocation, and emerging technology systems. TechFront360 has no financial or commercial relationship with any company referenced.