
Oak HC/FT’s lead investment signals a deeper capital shift: as financial AI becomes autonomous, the real bottleneck is no longer models — it is data reliability.
Spade, a financial AI infrastructure company operating in the transaction intelligence layer, has raised $40 million in Series B funding — positioning itself at a critical control point in the financial AI stack. The round, led by Oak HC/FT with participation from Andreessen Horowitz, Flourish, Gradient, NAventures, National Bank of Canada, and Y Combinator, reflects a broader reallocation of capital toward infrastructure layers that determine system reliability rather than surface-level intelligence.
At a surface level, the round appears modest in a market dominated by large-scale AI financings. From an investor perspective, however, it signals a more important shift: capital is moving away from model-centric bets toward the data layers those models depend on.
The underlying thesis is clear. Financial AI systems are unlikely to fail because they lack intelligence; they will fail because they cannot reliably interpret the data they are given. In that context, the companies that control how raw financial signals are transformed into structured, machine-readable truth occupy a position of disproportionate leverage.
Spade is positioning itself precisely at that layer.
The Signal: Capital Moving Beneath the Application Layer
Over the past two years, venture capital has concentrated heavily on visible layers of the AI stack — foundation models, copilots, and application-layer automation. These categories are capital-intensive and highly competitive, but they do not ultimately determine system reliability.
Spade represents a different category of investment. It operates in an invisible but foundational layer: the transformation of raw transaction strings into verified merchant intelligence that downstream systems can trust.
This layer sits between payment infrastructure and financial applications, increasingly acting as the interface between real-world economic activity and the AI systems tasked with interpreting it. As financial workflows become more autonomous, the importance of this translation layer increases materially.
For investors, the implication is straightforward:
👉 If the input layer is unreliable, no model advantage downstream is durable.
The Structural Problem: Financial Data as a Constraint Layer
Raw financial transaction data remains structurally incompatible with machine reasoning. Transactions are often represented as truncated or ambiguous strings, with inconsistent merchant identification, outdated category classifications, and incomplete location signals.
This is not a marginal inefficiency. It is a systemic constraint embedded in financial infrastructure.
Every downstream system — fraud detection, rewards attribution, compliance monitoring, and increasingly agentic AI systems — depends on resolving this ambiguity before it can act. Without that resolution, even advanced models produce outputs that are technically coherent but operationally unreliable.
Spade’s platform addresses this by transforming raw transaction data into structured, verified records in real time, effectively standardizing the input layer for financial AI systems.
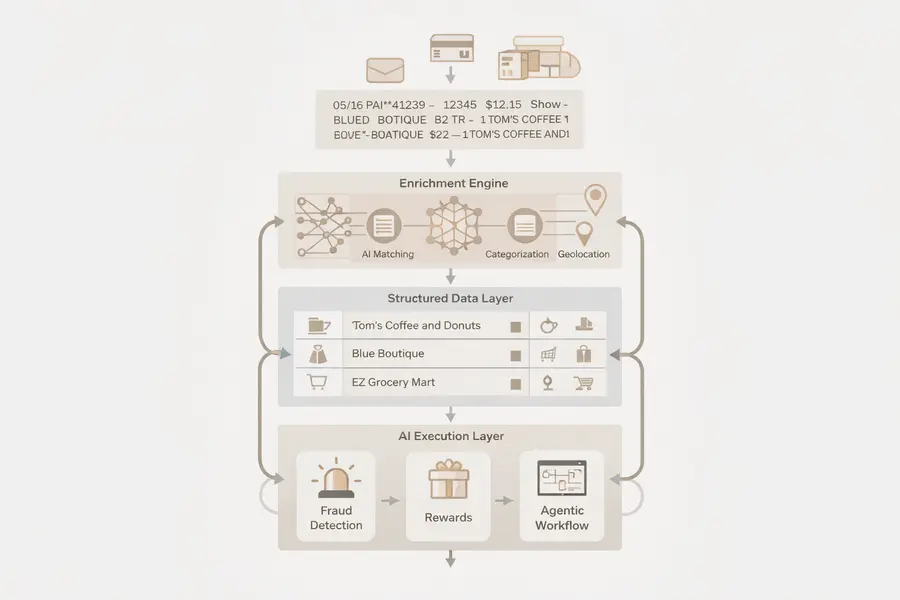
Why Investors Are Treating This as Infrastructure
The reframing of Spade from a data enrichment provider to an infrastructure company reflects a broader shift in investor thinking. As AI systems move toward autonomous execution, reliability becomes more valuable than capability.
Agentic financial systems — which detect signals, make decisions, and execute actions without human intervention — require high-confidence inputs. In these environments, data quality becomes the first-order constraint, with models and interfaces operating downstream.
Oak HC/FT’s lead position reflects this shift. The firm is not investing in a feature or workflow optimization layer, but in a control point that determines whether financial AI systems can operate safely and at scale. Increasingly, infrastructure investors are prioritizing layers that enforce data integrity, viewing them as more defensible than application-layer differentiation.
The Flywheel: Why the Data Layer Compounds
Spade’s competitive advantage is reinforced by scale. Processing billions of transactions monthly, with peak volumes reaching into the billions per day, the platform continuously improves its merchant resolution and classification accuracy.
Each transaction contributes signal, refining the system’s ability to resolve ambiguity and handle edge cases. Over time, this creates a compounding feedback loop in which scale improves performance, and improved performance drives further adoption.
For new entrants, this presents a structural barrier. Replicating the system requires not only engineering capability but sustained access to transaction volume at scale — a distribution challenge that cannot be solved through capital alone.
From Product to Infrastructure
Spade’s customer base — including Stripe, PayPal, Cash App, Mercury, Robinhood, and Bilt — is often cited as evidence of traction. More significant, however, is the depth of integration.
With more than 85 percent of customers deploying Spade across multiple workflows, the platform is no longer used as a point solution. It is embedded within core system architecture, marking a transition from product to infrastructure.
While the reported 470 percent year-over-year revenue growth reflects strong expansion, the more durable signal lies in integration depth. Infrastructure scales not only through new customers, but through increasing dependency within existing systems.
Positioning Within the Stack
Comparisons to Plaid are common but incomplete. Plaid operates at the connectivity layer, providing access to raw financial data. Its enrichment capabilities, while improving, remain secondary to that function.
Spade occupies a narrower and more specialized role: the precision intelligence layer that resolves raw data into usable form. In practice, the two are often used together — Plaid for access, Spade for interpretation.
This complementary positioning reduces direct competitive pressure while increasing integration stickiness. Rather than competing head-on with incumbents, Spade embeds itself into the layers they do not prioritize.
The Investor Signal
The composition of the investor group reinforces the infrastructure thesis. Oak HC/FT’s leadership signals institutional conviction in data-layer control points within financial systems, while participation from National Bank of Canada indicates growing demand from traditional financial institutions. Repeat participation from Andreessen Horowitz, Gradient, and Y Combinator reflects continued belief in the company’s long-term positioning.
Taken together, the round signals alignment around a clear investment view:
👉 As AI systems move toward execution, the layers that define data reliability become strategic assets.
The Constraint Layer
The investment case, however, is not without risk. Large incumbents such as Plaid and broader financial infrastructure providers retain the ability to expand deeper into enrichment over time. At the same time, financial institutions may seek to internalize data intelligence capabilities as AI becomes core to their operations.
Spade’s long-term position will depend on whether its data advantage compounds faster than incumbents can close the gap — a dynamic that has historically determined outcomes in infrastructure markets.
The Broader Pattern
Spade fits within a wider shift across AI infrastructure:
- Observability systems evolving into control layers
- Workflow automation transitioning into execution-layer AI
- Cloud architectures being rebuilt as AI-native infrastructure
Within this pattern, Spade represents the extension of that shift into data itself.
👉 Data is no longer a passive input. It is becoming an active infrastructure layer.
Conclusion
Spade’s $40 million round is not a bet on transaction enrichment as a feature. It is a capital allocation decision around data reliability as a control point within financial AI systems.
As those systems become more autonomous, the importance of that control point increases. Models may define how decisions are made, but data defines whether those decisions are correct.
And in AI systems, correctness begins with how reality is interpreted — making the data layer one of the most strategically valuable positions in the stack.